
Data Sources
Recent changes to data sources in Evidence
A recent Evidence release (Universal SQL, v24+) contains breaking changes for data source setup.
If you recently updated your Evidence version and are having issues setting up data sources, consult the migration guide
Overview of Data Sources
Evidence extracts all data sources into a common storage format (called Parquet) to enable querying across multiple data sources using SQL.
- To query against your data sources, you first need to extract the data into Parquet, using
npm run sources - Supported sources including SQL databases, flat data files (CSV etc), and non-SQL data sources (e.g. APIs)
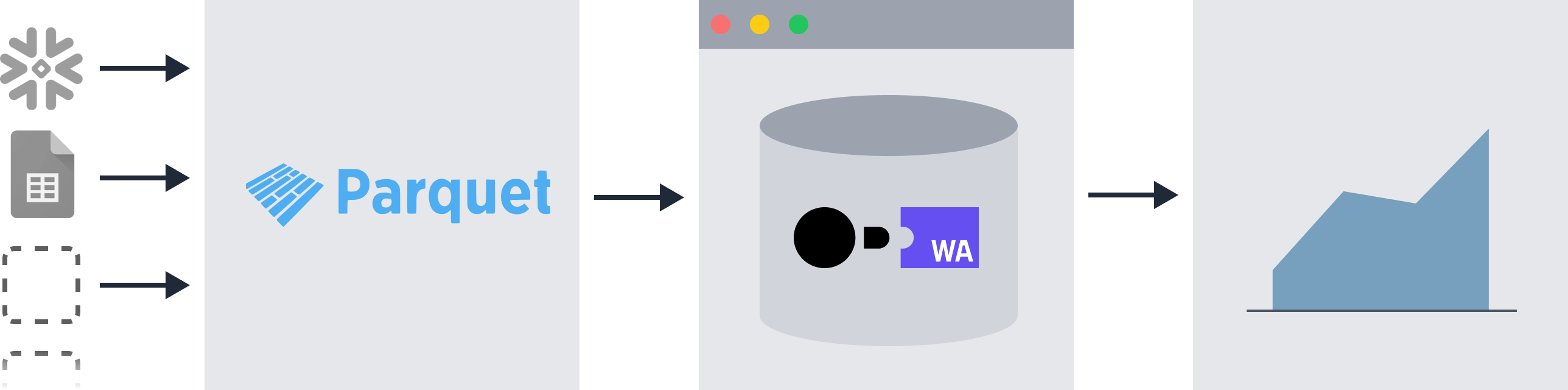
More information about the architecture design can be found in this article.
Connect your Data Sources
To connect your local development environment to a database:
- Run your evidence app with
npm run dev - Navigate to localhost:3000/settings
- Select your data source, name it, and enter required credentials
- (If required) Open the
connections.yamlfile inside/sources/[source_name]and add any additional configuration options - (If required) Add source queries
- Rerun sources with
npm run sources
Evidence will save your credentials locally, and run a test query to confirm that it can connect.
Connections to databases in production are managed via environment variables
Configure Source Queries
For SQL data sources, choose which data to extract by adding .sql files to the /sources/[source_name]/ folder.
N.B: These queries use the data source's native SQL dialect.
.-- sources/
`-- my_source/
|-- connection.yaml
`-- my_source_query.sqlEach of these .sql files will create a table that can be queried in Evidence as [my_source].[my_source_query].
Non-SQL data sources
For non-SQL data sources, configuring the data extracted is achieved in other ways. Refer to the documentation for the specific data source for details.
Run Sources
You can extract data from configured sources in Evidence using npm run sources. Sources will also rerun automatically if you have the dev server running and you make changes to your source queries or source configuration.
Working with Large Sources
In dev mode, if you have large sources which take a while to run, it can be helpful to only run the sources which have changed. There are a few ways to accomplish this:
- If your dev server is running, any changes you make to source queries will only re-run the queries which have changed
- Run a modified sources command to specify the source you want to run:
npm run sources -- --changedrun only the sources with changed queriesnpm run sources -- --sources my_sourcerunmy_sourceonlynpm run sources -- --sources my_source --queries query_one,query_tworunmy_source.query_oneandmy_source.query_twoonly
Increase Process Memory
If you are working with large data sources (~1M+ rows), your npm run sources process may run out of memory, with an error similar to this:
FATAL ERROR: Reached heap limit Allocation failed - JavaScript heap out of memoryOne way to circumvent this is to increase the amount of memory allocated to the process. The below command increases the memory to 4GB (the number is measured in MB), but you can set it arbitrarily up to the RAM of your machine
Mac OS / Linux
NODE_OPTIONS="--max-old-space-size=4096" npm run sourcesWindows
set NODE_OPTIONS=--max-old-space-size=4096 && npm run sourcesBuild Time Variables
You can pass variables to your source queries at build time using environment variables of the format EVIDENCE_VAR__variable_name=value.
.env
EVIDENCE_VAR__client_id=123Then in your source queries, you can access the variable using ${} syntax:
select * from customers
where client_id = ${client_id}This will interpolate the value of client_id into the query:
select * from customers
where client_id = 123Note that these variables are only accessible in source queries, not in file queries or queries in markdown files.
Supported data sources
Evidence supports:
- BigQuery
- Snowflake
- Redshift
- PostgreSQL
- Timescale
- Trino
- Microsoft SQL Server
- MySQL
- SQLite
- DuckDB
- MotherDuck
- Databricks
- Cube
- Google Sheets
- CSV
- Parquet
- & More
We're adding new connectors regularly. Create a GitHub issue or send us a message in Slack if you'd like to use Evidence with a database that isn't currently supported.
The source code for Evidence's connectors is available on GitHub
Data source specific info
All databases can be connected via the UI settings page as described above. Where relevant, additional information is provided below.
BigQuery
Evidence supports connecting to Google BigQuery by using the gcloud CLI, a service account and a JSON key, or an OAuth access token.
Logging in with the gcloud CLI
If you have the gcloud CLI installed, you can log in to BigQuery using the following command:
gcloud auth application-default loginEvidence will use the credentials stored by the gcloud CLI to connect to BigQuery.
Note: Since gcloud requires browser access, this method is only available when developing locally.
Create a Service Account Key
- Go to the Service Account Page and click on your project
- Add a name for your service account, then click Create
- Assign your service account a role for BigQuery (scroll down the role dropdown to find BigQuery roles).
- BigQuery User should work for most use cases.
- BigQuery Data Viewer may be required (depending on your organization's permissions settings in Google Cloud).
- Reach out to us if you run into issues or need help with BigQuery permissions.
- Click Continue, then click Done. You should see a table of users.
- Click on the email address for the service account you just created, then click the Keys tab
- Click Add Key, then Create New Key, then Create
- Google will download a JSON Key File to your computer
Logging in with an OAuth access token
If you have an access token but can't download the gcloud CLI on the device you're deploying on and don't want to use a service account, you can use an OAuth access token.
An OAuth access token can be generated by running the following command on a device with the gcloud CLI installed:
gcloud auth application-default print-access-tokenNote: This token will expire after 1 hour.
Now you can copy the access token and use it in your Evidence app.
Snowflake
Evidence supports connecting to Snowflake using a Snowflake Account, Key-Pair Authentication, Browser-Based SSO, or Native SSO through Okta. All Snowflake column names will be converted to lowercase in Evidence.
Snowflake Account
The Snowflake Account authentication method uses your Snowflake username and password to authenticate. If you don't have access to these, you will need to use one of the other authentication methods.
Key-Pair Authentication
The Key-Pair Authentication method uses a public/private key pair to authenticate. To use this method, you will need to generate a public/private key pair and upload the public key to Snowflake.
Browser-Based SSO
The Browser-Based SSO method uses a browser-based SSO flow to authenticate. To use this method, you will need to connect an SSO provider to your Snowflake account.
Native SSO through Okta
The Native SSO through Okta method uses Okta to authenticate. To use this method, you will need to have an Okta account with MFA disabled connected to your Snowflake account.
Redshift
The Redshift connector uses the Postgres connector under the hood, so configuration options are similar.
PostgreSQL
Some databases can be connected by using the Postgres connector, including Timescale.
SSL
To connect to a Postgres database using SSL, you may need to modify the SSL settings used. Once you have selected a PostgreSQL data connection type, you can set the SSL value as follows:
false: Don't connect using SSL (default)true: Connect using SSL, validating the SSL certificates. Self-signed certificates will fail using this approach.no-verify: Connect using SSL, but don't validate the certificates.
Other SSL options will require the use of a custom connection string. Evidence uses the node-postgres package to manage these connections, and the details of additional SSL options via the connection string can be found at the package documentation.
One scenario might be a Postgres platform that issues a self-signed certificate for the database connection, but provides a CA certificate to validate that self-signed certificate. In this scenario you could use a CONNECTION STRING value as follows:
postgresql://{user}:{password}@{host}:{port}/{database}?sslmode=require&sslrootcert=/path/to/file/ca-certificate.crtReplace the various {properties} as needed, and replace /path/to/file/ca-certificate.crt with the path and filename of your certificate.
Currently the UI does not support adding ssl with client certificates as authentication method. If you want to use this, you need to manually change your connection.yaml to:
name: mydatabase
type: postgres
options:
host: example.myhost.com
port: 5432
database: mydatabase
ssl:
sslmode: requireand your connection.options.yaml to:
user: "USERNAME_AS_BASE64"
ssl:
rejectUnauthorized: true
key: "USER_KEY_AS_BASE64"
cert: "USER_CERT_AS_BASE64"
Here you encode the full user key and cert file as base64 and put them in the correct options. If you do not want to verify the server certificate, for example because you have a self signed certificate, then change rejectUnauthorized to false.
Trino
Supported Authentication Types
While Trino supports multiple authentication types, the connector does currently only support the password based ones. Behind the scenes, the connector is using Basic access authentication for communicating with Trino.
HTTPS
To connect to a Trino installation that is accessible via HTTPS, you need to set the SSL option to true and the port to 443/8443 (unless you are using a non standard port for HTTPS, in which case you should use that instead).
Starburst Quickstart
Starburst, the company behind Trino, offers a SAAS solution where they run Trino for you. Once you have signed up and created a Trino cluster, you should be able to connect Evidence with the following configuration:
Host: <YOUR_DOMAIN>-<YOUR_CLUSTER_NAME>.galaxy.starburst.io
Port: 443
User: <YOUR_EMAIL>/accountadmin
SSL: true
Password: The password you use to login to your Starburst account
Alternatively, you can also create a service account at https://<YOUR_DOMAIN>.galaxy.starburst.io/service-accounts and use this to connect.
Microsoft SQL Server
Trust Server Certificate
The trustServerCertificate option indicates whether the channel will be encrypted while bypassing walking the certificate chain to validate trust. This option is disabled by default.
Encrypt
The encrypt option indicates whether SQL Server uses SSL encryption for all data sent between the client and server if the server has a certificate installed. Necessary for Azure databases.
Connection Timeout
The connection_timeout option indicates the time, in milliseconds, that a query can run before it is terminated. It defaults to 15000 ms.
MySQL
SSL
SSL options are:
false(default)trueAmazon RDS- A credentials object
SQLite
SQLite is a local file-based database. The SQLite file should be stored in the directory sources/[your_source_name]/.
DuckDB
DuckDB is a local file-based database. If using a persistent database, it should be stored in the directory sources/[your_source_name]/.
See the DuckDB docs for more information.
MotherDuck
Motherduck is a cloud-based DuckDB database.
To connect to MotherDuck, you will need a service token.
Databricks
Databricks is a cloud-based data lake. Evidence supports connecting to Databricks using a personal access token.
Cube
Cube offers semantic layer for your data. You can connect using the Cube SQL API.
Cube's API is PostgreSQL compatible, so you can use the Evidence PostgreSQL connector to connect to Cube.
You can find the credentials to connect to Cube on the BI Integrations page under the SQL API Connection tab (you may need to enable the SQL API first).
Google Sheets
The Google Sheets data source is a plugin, you first need to install the plugin.
Adding data from Google Sheets requires a a service account.
To create a service account, see the BigQuery instructions.
- Create a service account, and download the JSON key file
- Give the service account access to your Google Sheet by sharing the sheet with the service account's email address.
- Add the JSON key file to your Evidence app via the Settings page
- In the connections.yaml file, add the sheet id (which can be found in the URL of the Google Sheet, after
https://docs.google.com/spreadsheets/d/).
name: [your_source_name]
type: gsheets
options: {}
sheets:
[your_workbook_name]: [your_sheet_id]Query the sheet using the following syntax:
select * from [your_source_name].[your_workbook_name]_[your_tab_name]Where [your_tab_name] is the name of the tab in your Google Sheet, with spaces replaced by underscores.
CSV files
In Evidence, you can query local CSV files directly in SQL.
Get started by selecting the CSV connector on the Settings page in your app, naming it and then clicking "confirm changes".
Then copy any CSV files you want to query into sources/[your_csv_source_name]/. Your source names and csv files can only contain letters, numbers and underscores eg /my_source/my_csv_2024.csv
The section below applies to both CSV and Parquet files.
How to Query a CSV File
Evidence looks for CSV files stored in a sources/[your_csv_source_name]/ folder in the root of your Evidence project. You can query them using this syntax:
select * from your_csv_source_name.csv_file_nameSource Options
You can add DuckDB source options that are passed in as arguments to the read_csv() function.
Ensure there are no spaces in your source options you pass, and to use double quotes when passing strings
Troubleshooting
If you need help with connecting to your data, please feel free to send us a message in Slack.